
Le procedure di screening, se utilizzate per l’identificazione degli elementi stradali caratterizzati da valori anomali della frequenza incidentale (siti ad elevata incidentalità), possono essere validi strumenti di supporto per gli Enti Gestori delle reti stradali che hanno necessità di eseguire, in modo rapido ed efficiente, valutazioni sulla sicurezza oggettiva di ciascun elemento della rete, sia esso un arco o un’intersezione.
Questa esigenza è particolarmente sentita quando le risorse finanziarie disponibili per la programmazione degli interventi di manutenzione e di adeguamento funzionale delle infrastrutture sono limitate e devono essere utilizzate con oculatezza per ottenere la massima efficacia degli investimenti finalizzati al miglioramento del livello di sicurezza di reti infrastrutturali estese e complesse.
A tal proposito, in questo articolo viene presentata un’innovativa procedura di screening, applicata al caso delle strade extraurbane secondarie, che è basata su due diversi algoritmi di apprendimento automatico (Algoritmi di Machine Learning – AML).
In analogia con quanto avviene nelle tradizionali procedure di screening, detti algoritmi sono stati calibrati per poter classificare un sito stradale come “potenzialmente sicuro” o “suscettibile all’evento incidentale”, sulla base della storia incidentale e di un insieme di caratteristiche geometriche, funzionali e ambientali del sito in esame.
I due algoritmi di apprendimento automatico sono stati calibrati e validati sulla rete gestita dalla Regione Toscana, utilizzando un campione composto da 1.990 elementi stradali, sulla metà dei quali si è verificato almeno un incidente [1]; gli AML utilizzati sono denominati “Albero Decisionale” (Decision Tree) e “Foresta Casuale” (Random Forest); in particolare, l’algoritmo “Foresta Casuale” ha mostrato le migliori performance nella previsione della pericolosità di un sito, con un’accuratezza pari al 73,53%.
Gli algoritmi automatici proposti possono essere usati agevolmente per gestire in modo efficiente una rete stradale, consentendo di stilare una lista delle ispezioni preventive alla pianificazione degli interventi, come richiesto dal Decreto Legislativo 35/2011 [2].
La definizione di screening
Il manuale americano della sicurezza stradale [3] individua le procedure di screening come parte cruciale del ciclo di gestione della sicurezza stradale. Lo screening è una metodologia di analisi, che può essere utilizzata per lo studio di una rete stradale con lo scopo di individuare gli elementi più critici e che necessitano di interventi di miglioramento della sicurezza.
Esso può essere definito una metodologia a basso costo perché è caratterizzato dall’assenza di ispezioni in situ ed è basato unicamente sul database storico e su strumenti di analisi opportunamente calibrati.
Questi strumenti hanno come input una combinazione di diverse informazioni, relative al sito stradale, e forniscono come output due possibili risposte: “Elemento con elevata incidentalità” o “Elemento con bassa incidentalità”.
La procedura di screening si conclude perciò con l’individuazione di un campione ristretto di siti stradali potenzialmente critici ossia con maggiore propensione ad essere sede di un evento incidentale; ne risulta evidente che le ispezioni in situ e gli eventuali interventi di mitigazione del rischio dovranno essere eseguiti con priorità su questi siti.
L’ipotesi
In questa ricerca è stato ipotizzato che il potenziale verificarsi di un incidente possa essere messo in relazione con le caratteristiche geometriche e funzionali di un sito stradale.
Sulla base di questa ipotesi, gli AML vengono opportunamente calibrati sulla base della reale storia incidentale degli elementi, desunta dalle informazioni disponibili su un periodo temporale sufficientemente lungo, assunto pari a cinque anni.
Infatti, cinque anni corrisponde al periodo generalmente richiesto per un’analisi di incidentalità che possa effettivamente mettere in luce le reali condizioni di sicurezza di un’infrastruttura, mostrando se essa sia sede di criticità che possano inficiare la sicurezza degli utenti.
La rete analizzata
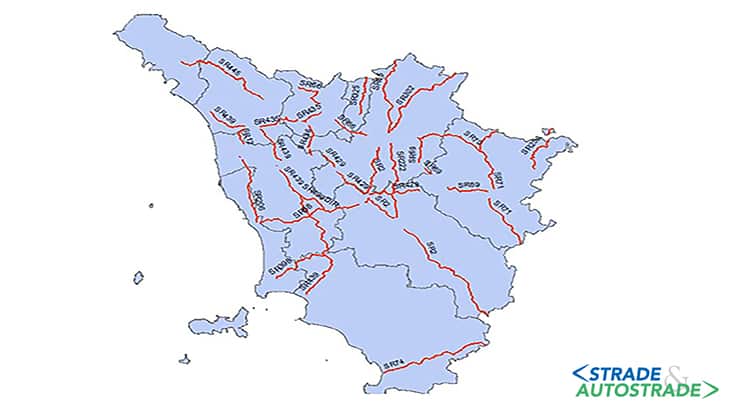
La rete investigata è quella gestita dalla Regione Toscana, che si estende per più di 1.000 km (Figura 2 sopra). La rete è costituita da circa 1.990 elementi stradali, sulla metà dei quali (995) si è verificato almeno un incidente dal 2012 al 2016; sul campione analizzato, è stato rilevato un numero totale di 5.094 incidenti, con 7.437 feriti e 113 decessi. Sulla restante metà degli elementi non sono stati registrati incidenti.
La metodologia
I fattori di input
La Regione Toscana ha fornito tutti i dati sui volumi di traffico, sugli incidenti registrati nel periodo 2012-2016 e sulle caratteristiche geometriche e ambientali delle infrastrutture, necessari per la definizione delle variabili di input indipendenti.
Dopo una loro elaborazione per il tramite di piattaforme GIS (Geographical Information Systems), la rete è stata suddivisa in elementi stradali omogenei (ciascuno avente lunghezza pari a circa 500 m) per caratteristiche geometriche e funzionali.
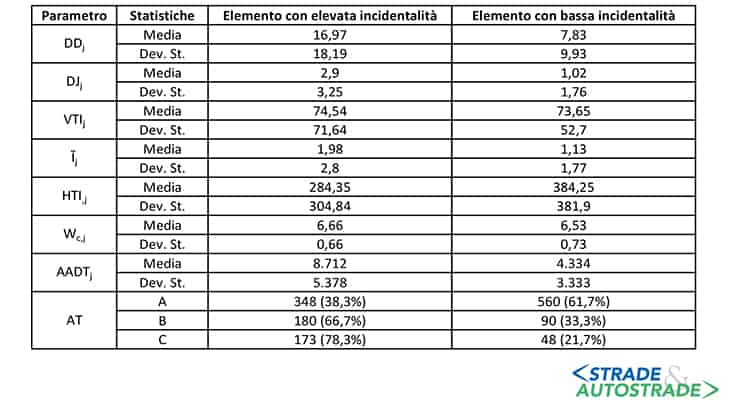
L’elenco seguente riporta i parametri di input:
- tipo di Area, AT: attraverso una sovrapposizione con le aree urbane, la rete stradale è stata segmentata in tre diversi tipi di area:
-
- elementi stradali completamente esterni alle aree edificate;
- elementi stradali completamente all’interno di aree edificate;
- elementi stradali situati ai confini amministrativi delle aree edificate.
- Traffico Giornaliero Medio Annuo, AADTj;
- Larghezza media della carreggiata, Wc,j;
- Pendenza longitudinale media della livelletta Īj;
- Indice di tortuosità planimetrica, HTIj;
- Indice di tortuosità altimetrica, VTIj;
- Densità degli accessi, DDj;
- Densità delle intersezioni, DJj.
La Figura 3 riporta i parametri statistici di ciascuna variabile indipendente per le due condizioni di stato degli elementi utilizzati per istruire e calibrare gli algoritmi.
Gli algoritmi di apprendimento automatico
Come anticipato, gli AML possono essere sfruttati come strumenti di supporto alle decisioni grazie alla loro capacità di modellare fenomeni complessi.
Negli ultimi anni, nel campo dell’Ingegneria dei Trasporti, essi sono sempre più utilizzati; si trovano numerose applicazioni sulla previsione della severità incidentale [4, 5 e 6], studi in merito alla previsione di incidenti in tempo reale [7, 8, 9, 10 e 11] e ricerche il cui obiettivo è individuare le cause che concorrono in un evento incidentale [12].
I sottoparagrafi che seguono descrivono gli AML utilizzati in questa ricerca e la metodologia di valutazione delle prestazioni.
L’Albero Decisionale
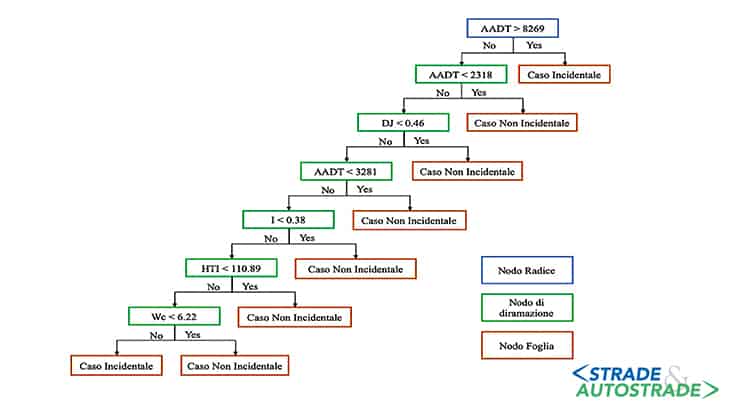
L’Albero Decisionale [13] è un AML gerarchico, non parametrico, con una struttura ad albero, che suddivide ripetutamente il set di dati in zone omogenee, chiamate nodi (Figura 4).
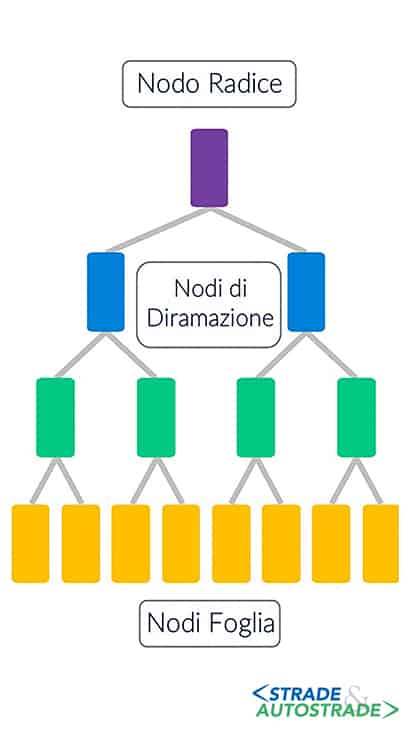
Le regole di decisione da seguire per la divisione di ciascun nodo vengono apprese dall’algoritmo direttamente ed in maniera totalmente automatica [14], deducendole dai dati disponibili (il Training set).
I vantaggi derivanti dall’utilizzo degli Alberi Decisionali sono i seguenti:
- forniscono una soluzione interpretabile delle previsioni mediante uno schema ad albero;
- sono insensibili alle variabili irrilevanti e ai valori anomali (Outliers);
- consentono di gestire input numerici e categorici (Sì/No, Debole/Medio/Forte, …).
Dopo che l’Albero Decisionale è stato calibrato e ottimizzato, si ottiene un algoritmo con sette regole di decisione e otto nodi foglia. La Figura 5 mostra lo schema dell’Albero Decisionale.
La “Foresta Casuale”
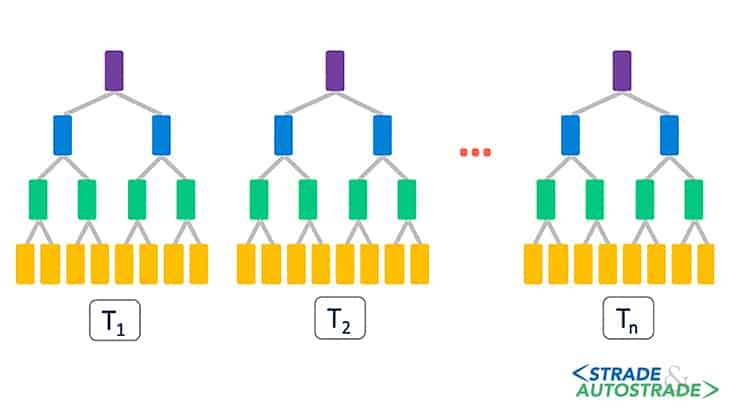
L’algoritmo “Foresta Casuale” è stato introdotto da Breiman [15] e appartiene sempre all’insieme degli AML con struttura ad albero. In questo algoritmo, diversamente dal precedente, vengono istruiti e calibrati un elevato numero di alberi decisionali, che operano dunque in parallelo (Figura 6).
L’algoritmo “Foresta Casuale” è in grado di istruire ogni albero decisionale con un diverso set di osservazioni e con un diverso numero e tipo di fattori di input; in questo modo, ogni albero sarà indipendente e diverso dagli altri.
L’elevato numero di alberi e la loro indipendenza fa sì che le previsioni dell’algoritmo “Foresta Casuale” siano molto accurate; a tal fine, viene sfruttato il cosiddetto parere della folla, la cui opinione media vale più dell’opinione di un singolo Esperto.
La media aritmetica delle previsioni dei singoli alberi fornisce la previsione finale dell’algoritmo; in questo studio, sono stati considerati 500 alberi decisionali.
Le metriche di valutazione
Per la valutazione dei risultati degli AML, è stato utilizzato un set completo di metriche.
Si definiscono:
- CP, numero di Corretti Positivi, ovvero i siti stradali “ad elevata incidentalità” per i quali gli AML forniscono lo stesso riscontro. Sono dunque il numero delle corrette previsioni degli AML per quanto concerne i “casi incidentali”;
- CN, numero di Corretti Negativi, ovvero i siti stradali “a bassa incidentalità”, per i quali gli AML forniscono lo stesso riscontro. Sono dunque il numero delle corrette previsioni degli AML per quanto concerne i “casi non incidentali”;
- FP, numero di Falsi Positivi, ovvero i siti stradali “a bassa incidentalità”, per i quali gli AML forniscono erroneamente una diversa risposta (“elevata incidentalità”). Gli FP sono i cosiddetti “Falsi Allarmi”;
- FN, numero di Falsi Negativi, ovvero i siti stradali “ad elevata incidentalità” per i quali gli AML forniscono erroneamente una diversa risposta (“bassa incidentalità”).
Di conseguenza, quando un AML produce una corretta previsione, essa andrà a costituire il numero dei CP o dei CN. Se la previsione non è corretta, invece, essa andrà a comporre l’insieme dei FP e FN. Sulla base dei suddetti parametri, si definisce l’accuratezza degli AML:
![]()
che rappresenta accuratamente le prestazioni globali degli AML. Si definisce anche la Precisione:
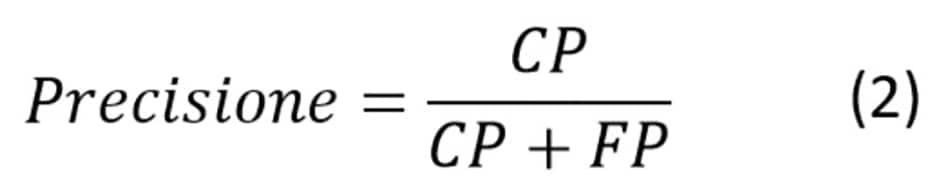
che mostra la bontà delle previsioni dei Casi Incidentali: maggiore è la precisione, minore sarà il numero di “falsi allarmi”, ossia quei siti che sono stati classificati come pericolosi ma che in realtà non lo sono.
La Sensitività è il rapporto tra le istanze positive che vengono correttamente rilevate dal classificatore; pertanto, maggiore è la sensitività, maggiore sarà la qualità del classificatore nel rilevare istanze positive:
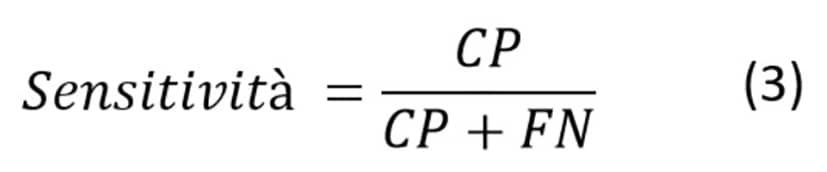
Il punteggio F1 è la media armonica della Precisione e della Sensitività; può essere utilizzato per confrontare diversi classificatori poiché combina le due metriche in una sola. Ne consegue che un classificatore valido ha un punteggio F1 soddisfacente solo se ha alta precisione e sensitività elevata:
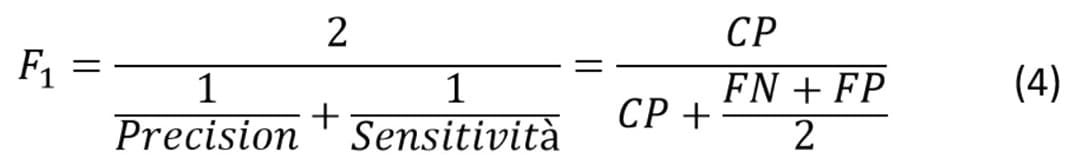
Inoltre, gli AML sono stati giudicati e confrontati costruendo la Matrice di Confusione, che ha dimensione 2×2 e riporta le istanze CP, CN, FP e FN come in Figura 7.
Nella Matrice di Confusione la prima riga rappresenta il numero di “Casi Incidentali” osservati, suddivisi in previsioni corrette da parte degli AML (CP) e quelle errate (FN), mentre la seconda riga riporta il numero dei “Casi Non Incidentali” osservati, suddivisi in previsione errata (FP) e previsione corretta (CN).
Un buon algoritmo previsionale si riflette in una Matrice di Confusione in cui la maggior parte delle istanze sono sulla diagonale principale (ovvero la maggior parte delle previsioni è del tipo CP o CN).

Risultati e conclusioni
I risultati sono presentati e discussi in termini di capacità previsionali degli AML, ossia i valori delle metriche (equazioni precedentemente riportate) sono state computate a seguito dell’utilizzo degli AML calibrati su un set di dati a loro ancora sconosciuto.
Questo set di dati si definisce Test set e permette di verificare se gli AML siano stati ben calibrati prima di essere effettivamente adottati dall’Ente gestore. Il Test set considerato si compone di 297 siti “ad elevata incidentalità” e 300 siti a “bassa incidentalità”.
Precisione, Sensitività e punteggio F1
La Figura 8 mostra, in fase di test, la Precisione, la Sensitività e il punteggio F1 per i due AML calibrati.
Essa dimostra che nella fase di test gli AML presentano adeguate capacità previsionali; in termini quantitativi, per quanto riguarda i siti con suscettibilità all’evento incidentale, l’Albero Decisionale riporta la massima Precisione (0,75), mentre la Foresta Casuale la massima Sensitività (0,71).
Al contrario, nel rilevamento dei siti potenzialmente sicuri, la Precisione è massima nella Foresta Casuale (0,72) mentre la Sensitività più elevata (0,79) spetta all’Albero Decisionale.
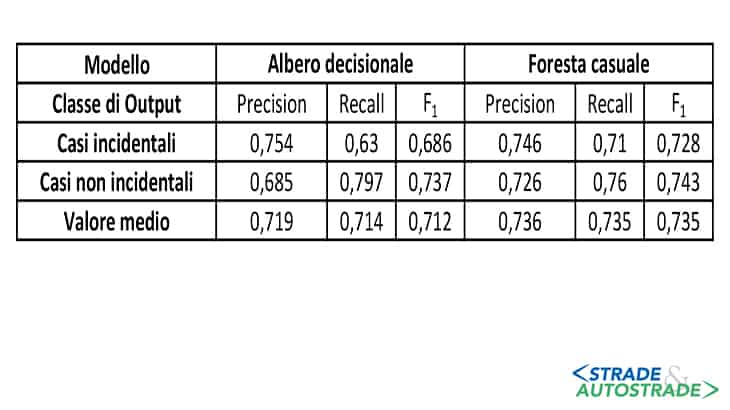
Il classificatore che presenta le metriche medie più elevate è la Foresta Casuale. In effetti, sono stati osservati la massima Precisione (0,73), la massima Sensitività (0,73) e il massimo Punteggio F1 (0,73).
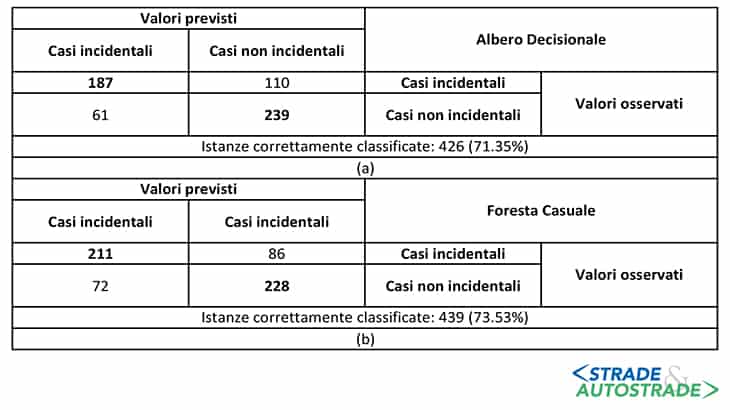
Le Matrici di Confusione
La Figura 9 riporta le Matrici di Confusione calcolate durante la fase di test degli AML. Nella parte inferiore di ogni matrice di confusione, viene riportato il numero di istanze correttamente classificate (ovvero la Accuratezza del classificatore).
La Foresta Causale prevede correttamente il numero più alto di “Casi Incidentali” (211 istanze su 297). I “Casi Non Incidentali” sono previsti con maggior accuratezza dall’Albero Decisionale (239 su 300). La massima Accuratezza complessiva (73,53%) è mostrata dalla Foresta Casuale, con 439 istanze su 597 campioni correttamente classificati.
Gli AML si sono dimostrati un appropriato strumento di supporto per l’Ente gestore, che avrebbe teoricamente individuato circa il 74% dei siti suscettibili all’evento incidentale con una tecnica a bassissimo costo, basandosi esclusivamente sulla storia incidentale e sulle caratteristiche geometriche e funzionali dei siti stradali che esso gestisce.
A seguito di questi risultati così incoraggianti, le Autorità stradali potrebbero prendere in considerazione l’uso degli algoritmi di apprendimento automatico per la previsione delle criticità legate al livello di sicurezza stradale e per pianificare con criteri di maggior oggettività l’attività di manutenzione stradale. Il presente articolo è estratto dallo studio di N. Fiorentini e M. Losa [16].
Bibliografia
[1]. N. Fiorentini – “Criteri per la definizione di una lista di priorità di intervento per l’adeguamento funzionale delle Strade Regionali”, Tesi di Laurea Magistrale, Università di Pisa, https://etd.adm.unipi.it/t/etd-09292017-183027/, 2017.
[2]. MIT – Decreto Legislativo n° 35/2011 “Gestione della sicurezza delle infrastrutture stradali”, 2011.
[3]. AASHTO – “Highway Safety Manual, 1st Edition, 2010.
[4]. N. Fiorentini, M. Losa – “Handling imbalanced data in road crash severity prediction by machine learning algorithms”, Infrastructures, 5(7), 61, doi:10.3390/infrastructures5070061, 2020.
[5]. A. Iranitalab, A. Khattak – “Comparison of four statistical and machine learning methods for crash severity prediction”, Accid. Anal. Prev., 108, 27-36, doi:10.1016/j.aap.2017.08.008, 2017.
[6]. S. Mokhtarimousavi, J.C. Anderson, A. Azizinamini, M. Hadi – “Improved support vector machine models for work zone crash injury severity prediction and analysis”, Res. Artic. Transp. Res. Rec., 2673, 680-692, doi:10.1177/0361198119845899, 2019.
[7]. F. Basso, L.J. Basso, F. Bravo, R. Pezoa – “Real-time crash prediction in an urban expressway using disaggregated data”, Transp. Res. Part C Emerg. Technol., doi:10.1016/j.trc.2017.11.014, 2018.
[8]. P. Li, M. Abdel-Aty, J. Yuan – “Real-time crash risk prediction on arterials based on LSTM-CNN”, Accid. Anal. Prev., doi:10.1016/j.aap.2019.105371, 2020.
[9]. A. Theofilatos, C. Chen, C. Antoniou – “Comparing machine learning and deep learning methods for real-time crash prediction”, Transp. Res. Rec., 2673, 169-178, doi:10.1177/0361198119841571, 2019.
[10]. J. You, J. Wang, J. Guo – “Real-time crash prediction on freeways using data mining and emerging techniques”, J. Mod. Transp., 25, 116-123, doi:10.1007/s40534-017-0129-7, 2017.
[11]. J. Yuan, M.A. Abdel-Aty, Y. Gong, Q. Cai – “Real-time crash risk prediction using long short-term memory recurrent neural network”, Transp. Res. Rec. J. Transp. Res. Board, 2673, 314-326, doi:10.1177/0361198119840611, 2019.
[12]. M. Schlogl, R. Stütz, G. Laaha, M. Melcher – “A comparison of statistical learning methods for deriving determining factors of accident occurrence from an imbalanced high resolution dataset”, Accid. Anal. Prev., 127, 134-149, doi:10.1016/J.AAP.2019.02.008, 2019.
[13]. L. Breiman, J.H. Friedman, R.A. Olshen, C.J. Stone – “Classification and Regression Trees.”, 2nd ed. Chapman & Hall/CRC, Taylor & Francis Group, 1984.
[14]. W.Y. Loh, Y.S. Shih – “Split selection methods for classification trees”, Vol. 7, 1997.
[15]. L. Breiman – “Random forests”, Mach. Learn, doi org/10.1023/A:101 0933404324, 2001.
[16]. N. Fiorentini, M. Losa – “Long-term-based road blackspot screening procedures by machine learning algorithms”, Sustainability, 12(15), 5972, doi:10.3390/su12155972, 2020.
> Se questo articolo ti è piaciuto, iscriviti alla Newsletter mensile al link http://eepurl.com/dpKhwL <